AI Benchmarks & Leaderboard — 2026-04-28
The past week in AI benchmarks was defined by DeepSeek's surprise V4 preview release, which claims to have nearly closed the gap with frontier closed-source models — while markets reacted with muted enthusiasm compared to last year's shock. Meanwhile, the Artificial Analysis leaderboard shows GPT-5.5 holding the top intelligence spot, with a cluster of models from Anthropic and Google close behind. New open-source contenders including Kimi K2.6 and Qwen3.5 are pushing cost-performance ratios to new lows.
AI Benchmarks & Leaderboard — 2026-04-28
New Model Releases & Updates
DeepSeek V4 (Preview) by DeepSeek
- Type: Open-source, large language model (architecture details not fully disclosed at preview stage)
- Key benchmarks: Claims to have "almost closed the gap" with current leading models on reasoning benchmarks; described as more efficient and performant than DeepSeek V3.2 due to architectural improvements
- vs. Previous best: Narrows the gap significantly versus GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro on reasoning tasks; Fortune noted that "the narrow gap between DeepSeek and leading U.S. models raises questions about OpenAI's and Anthropic's competitive moat"
- What's notable: Released on April 24, 2026 as a preview with deep integration for Huawei chip technology, underscoring China's push for AI hardware independence. Pricing is described as "rock-bottom." Market reaction was subdued compared to DeepSeek's viral January 2025 breakthrough, suggesting the landscape has normalized.

GPT-5.5 by OpenAI
- Type: Closed-source
- Key benchmarks: Artificial Analysis Intelligence Index score of 60 (xhigh) and 59 (high), ranking #1 and #2 respectively across all models on the leaderboard
- vs. Previous best: Holds the top two intelligence positions, ahead of Claude Opus 4.7 and Gemini 3.1 Pro Preview
- What's notable: Leads the field in overall intelligence benchmarking per Artificial Analysis; two distinct serving tiers (xhigh and high) both occupy the top of the leaderboard as of the April 27 snapshot
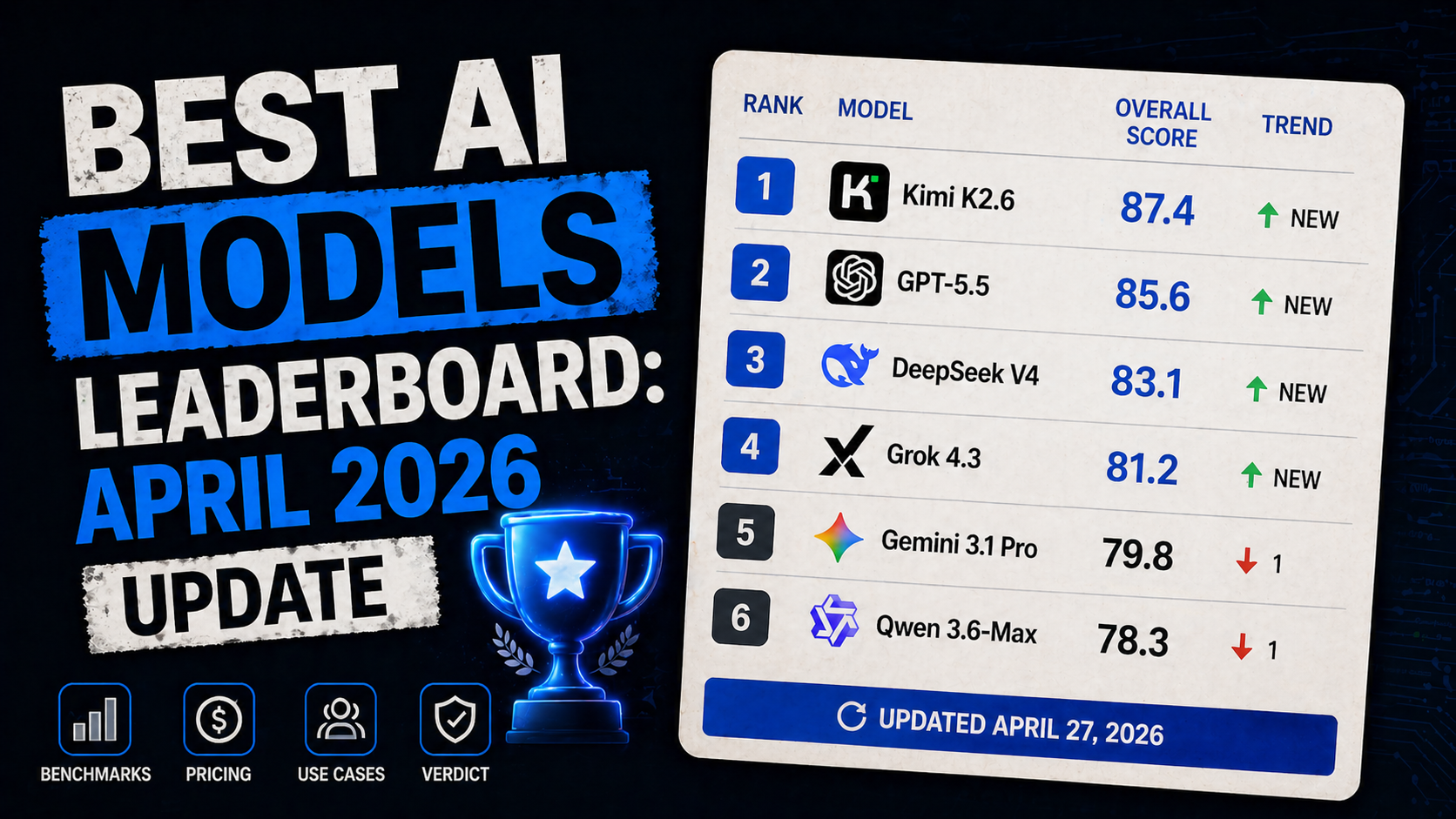
Kimi K2.6 by Moonshot AI
- Type: Closed-source
- Key benchmarks: Listed among models that dropped in the same 5-day window as GPT-5.5, DeepSeek V4, and Grok 4.3; full benchmark table available in the April 27, 2026 leaderboard update
- vs. Previous best: Part of a fresh wave of frontier-level releases in late April 2026
- What's notable: Moonshot AI's Kimi K2.6 joins a burst of late-April releases; specific benchmark numbers were not independently confirmed in reviewed sources
Mercury 2 by (provider not specified in sources)
- Type: Closed-source; optimized for speed
- Key benchmarks: 684.1 tokens per second — fastest model tracked by Artificial Analysis as of this week
- vs. Previous best: Outpaces second-fastest Granite 3.3 8B (389.7 t/s) by a wide margin
- What's notable: Raw inference speed champion; relevant for latency-sensitive production deployments
Leaderboard Snapshot
Frontier Models (Closed-Source)
| Model | Provider | Notable Strengths | Key Score |
|---|---|---|---|
| GPT-5.5 (xhigh) | OpenAI | Highest overall intelligence | Intelligence Index: 60 |
| GPT-5.5 (high) | OpenAI | Second-highest overall intelligence | Intelligence Index: 59 |
| Claude Opus 4.7 (Adaptive Reasoning, Max Effort) | Anthropic | Reasoning, adaptive compute | Intelligence Index: 57 |
| Gemini 3.1 Pro Preview | Multimodal, long context | Intelligence Index: 57 | |
| GPT-5.4 (xhigh) | OpenAI | Strong reasoning, coding | Intelligence Index: 57 |
Open-Source Leaders
| Model | Parameters | Notable Strengths | Key Score |
|---|---|---|---|
| DeepSeek V4 (Preview) | Not disclosed | Reasoning, near-frontier benchmark performance | Claimed near-frontier on reasoning |
| Qwen3.5 (0.8B, Reasoning) | 0.8B | Ultra-affordable: $0.02/1M tokens blended | Most affordable model tracked |
| Granite 3.3 8B (Non-reasoning) | 8B | Speed: 389.7 t/s | 2nd fastest model tracked |
| Granite 4.0 H Small | Not disclosed | Speed: 338.7 t/s | 3rd fastest model tracked |
| Qwen3.5 (0.8B, Non-reasoning) | 0.8B | Lowest cost tier: $0.02/1M tokens | Tied most affordable |
Benchmark Deep Dive
DeepSeek V4 vs. Frontier: What "Closing the Gap" Actually Means
The biggest benchmark story this week is DeepSeek's V4 preview claim that it has "almost closed the gap" with current leading models on reasoning benchmarks. Released April 24, DeepSeek states that V4 outperforms its own V3.2 due to architectural improvements and achieves near-parity with both open and closed frontier models on reasoning-specific evaluations.
What makes this significant is the cost angle: Fortune reported that DeepSeek V4's pricing is "rock-bottom" — continuing the Chinese startup's pattern of delivering high capability at aggressively low cost. This directly pressures the commercial moat of OpenAI and Anthropic, whose highest-capability models (GPT-5.5 and Claude Opus 4.7) hold meaningful intelligence-index leads on third-party benchmarks like Artificial Analysis, but at substantially higher price points.
However, the market reaction tells an important story about benchmark maturity. Reuters reported on April 27 that investor response to the V4 preview was "subdued compared with DeepSeek's outsized global breakthrough last year." This reflects two things: the novelty of near-frontier open-source performance has worn off, and practitioners have learned to wait for full releases before drawing conclusions from preview benchmark claims. As MIT Technology Review noted in its April 27 download, V4 will be tested against GPT-5.x, Claude, and Gemini in coming weeks.
For practitioners, the key question is whether V4's "near-frontier" reasoning performance holds up on independent evaluations — particularly on hard science (GPQA), mathematics (MATH), and agentic coding (SWE-bench) — or whether the gap is narrower on curated internal benchmarks. The Huawei chip integration also raises a practical consideration: enterprise users outside China may face deployment constraints tied to hardware availability.

Analysis & Trends
- State of the art: GPT-5.5 leads on overall intelligence (Artificial Analysis Intelligence Index). Claude Opus 4.7 and Gemini 3.1 Pro Preview are within 3 points. DeepSeek V4 previews near-frontier reasoning capability from the open-source world.
- Open vs. Closed gap: The gap continues to narrow. DeepSeek's V4 claims near-parity on reasoning benchmarks with the best closed models. Qwen3.5 (Alibaba) is the cost-per-token leader among tracked open-weight models at $0.02/1M tokens blended — a level that essentially commoditizes inference at the small end of the capability range.
- Cost-performance: Mercury 2's 684 tokens/sec throughput sets a new speed benchmark for production deployments. Qwen3.5 0.8B at $0.02/1M tokens represents the floor for affordable inference. DeepSeek V4 claims competitive quality at low cost, though independent verification is pending.
- Emerging patterns: Two clear trends dominate this week — (1) China's open-source AI push is intensifying, with both DeepSeek V4 and Qwen3.5 demonstrating that Western closed-model pricing power faces structural pressure; (2) Hardware sovereignty is emerging as a benchmark axis, with DeepSeek's Huawei chip integration signaling that inference infrastructure increasingly shapes which models practitioners can actually deploy.
What to Watch Next
- DeepSeek V4 independent evaluations: Full independent benchmark results (GPQA, MATH, SWE-bench, HumanEval) are needed to confirm V4's claimed near-frontier reasoning performance — watch for third-party evaluations from Artificial Analysis, LMSYS Chatbot Arena, and academic groups in the coming days.
- Kimi K2.6 and Grok 4.3 full benchmark disclosure: Both models dropped in the same five-day window as GPT-5.5 and DeepSeek V4; detailed benchmark numbers and independent evaluations have not yet surfaced in reviewed sources — these are the next data points to watch for leaderboard placement.
- IQ-benchmark methodology scrutiny: Visual Capitalist published a ranking of AI models by Mensa Norway IQ scores (TrackingAI benchmark) this week, reigniting debate about whether general-intelligence proxies like IQ scores provide meaningful signal beyond established benchmarks — worth monitoring as practitioners assess benchmark diversity.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

