Agent Harness Engineering Weekly Report — 2026-05-29
The AI agent development community released reinforced guidelines and framework comparisons this week. OpenAI's harness engineering architecture and Anthropic's context management strategy for long-running agents are drawing attention, alongside new benchmark research on security guardrails and tool-use validation patterns. As of mid-2026, the selection criteria between major frameworks like LangGraph, CrewAI, and AutoGen are becoming clearer.
Agent Harness Engineering Weekly Report — 2026-05-29
Scope note: This report covers AI Agent Harness Engineering — the software scaffolding, orchestration frameworks (LangGraph, DSPy, CrewAI, AutoGen, Claude Agent SDK, OpenAI Agents SDK), tool-use patterns, guardrails, memory systems, and evaluation infrastructure for production LLM agents. It is NOT about physical wire harnesses, cabling, or automotive electrical systems.
This Week's Headlines
-
Anthropic releases context management strategy for long-running agents: Claude Agent SDK's compression capabilities and memory optimization patterns are now fully documented, positioning them as a key solution for production environments where sustained operations without cost control are impossible.
-
AI agent security guardrails benchmark published: New evaluation comparing DKnownAI Guard, AWS Bedrock Guardrails, Azure Content Safety, and Lakera Guard quantifies differences in tool-execution validation and prompt-level attack defense.
-
GitHub community posts comprehensive harness engineering guide: The ai-boost/awesome-harness-engineering repository publishes an interactive reference consolidating complete runtime discipline for production agents, covering loop budgets, typed tools, permission gating, compression-aware memory, and prompt caching batching.
-
DEV Community: Seven frameworks, real-world lessons learned: A developer compares framework selection criteria and production deployment patterns based on experience building agents with LangGraph, CrewAI, AutoGen, and others.
Framework & Tooling Updates
Claude Agent SDK — Context Compression & Memory Management
- What's new: Compression API for long-running agent execution, persistent permission systems, and a five-layer safety architecture. Includes prompt-level guardrails, schema-level tool gating, runtime approval systems, tool-level validation, and custom lifecycle hooks.
- Why it matters: Enables agents to complete work in long-duration tasks where context window costs grow exponentially. External tool auto-discovery and lazy loading via MCP (Model Context Protocol) ensure scalability.
- Migration notes: Existing agents require explicit compression policy configuration. Tool declarations now mandate schema validation.
OpenAI Codex Orchestration Standard — Symphony Spec
- What's new: Open-source standard auto-generating repository structure, CI configuration, formatting rules, and package manager setup. GPT-5–based Codex CLI learns existing templates to automate project scaffolding.
- Why it matters: Enables coding agents to independently configure their own repository harnesses, creating an automated loop where agents build harnesses for agents. Spreads consistent harness design patterns.
- Migration notes: Existing projects need template updates to align with Symphony spec. Version pinning is critical for code generation consistency.
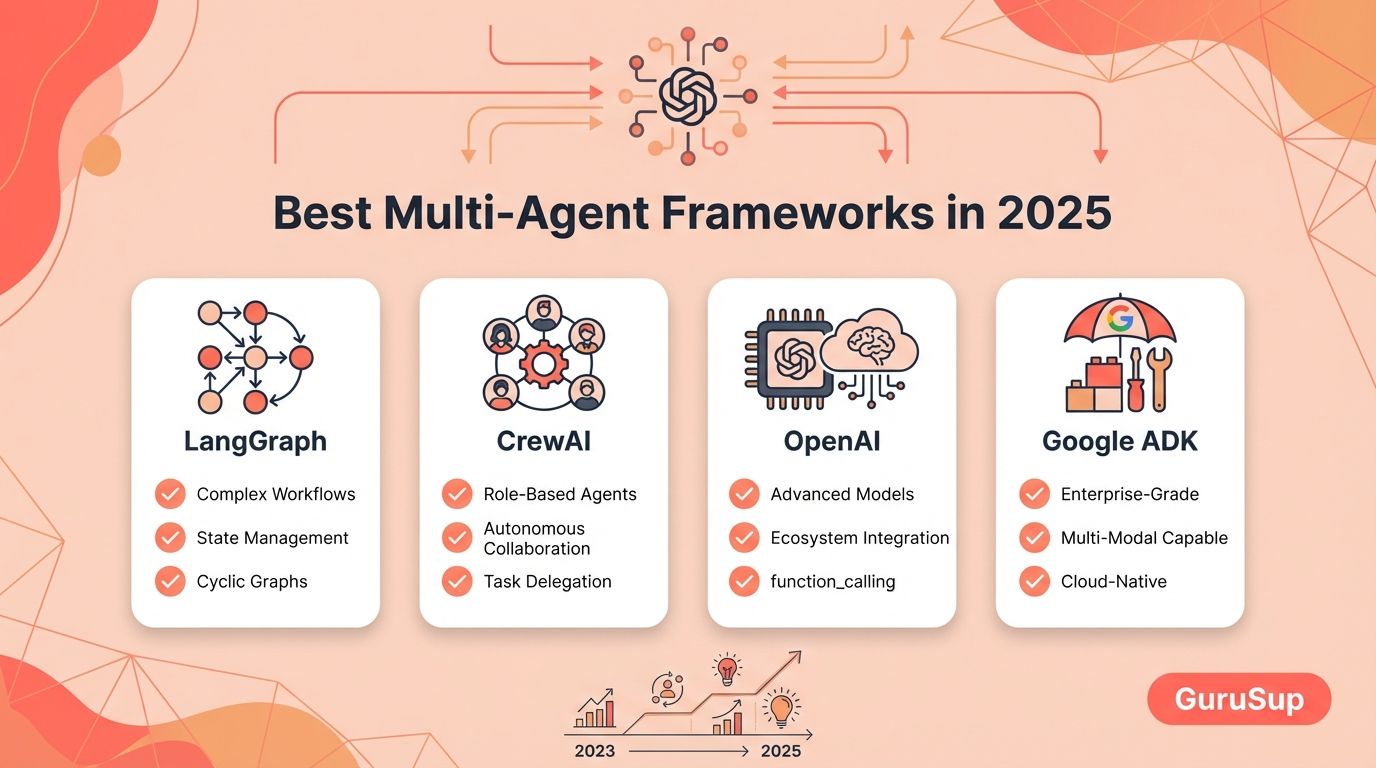
Multi-Agent Framework Comparison (2026)
- What's new: Comprehensive guide comparing six major frameworks: OpenAI Agents SDK, LangGraph, CrewAI, AutoGen/AG2, Google ADK, and others. Each framework evaluated on complexity, GitHub stars, and use-case fit.
- Why it matters: LangChain leads on flexibility, LlamaIndex excels at RAG, CrewAI's strength is role-based orchestration. Framework choice is no longer abstract—concrete tradeoff analysis is now possible.
- Migration notes: Replacing frameworks in existing systems is costly. An adapter layer abstracting tool interfaces and memory systems is needed.
Research & Evaluation
AI Agent Systems: Architectures, Applications, and Evaluation (arXiv:2601.01743)
- Authors / Org: Academic consortium, January 2026
- Core finding: Task suites, human preference metrics, constrained success, robustness and security, and reproducibility are critical challenges in agent evaluation and benchmarking. Tool-action validation, scalable memory/context management, and agent-decision interpretability remain open problems.
- Implication for harness design: Harness layers must implement tool-call logging, periodic memory compression checkpoints, and auditable decision traces. Evaluations require clear success definitions and seed control to ensure reproducibility.
Building AI Coding Agents for the Terminal (arXiv:2603.05344)
- Authors / Org: Anthropic research, March 2026
- Core finding: Real-world terminal agents require a five-layer safety architecture (prompt → schema → runtime approval → tool → lifecycle). Dual-agent separation (planning agent vs. execution agent) ensures schema-gating reliability. External tools discovered via MCP registry pattern.
- Implication for harness design: Single-agent designs have high security costs; role separation is essential. Persist permissions to eliminate repeated approval overhead. Layer prompt-level attack defense (prompt injection) separately from tool-level defense (malicious scripts).
A Comparative Evaluation of AI Agent Security Guardrails (arXiv:2604.24826)
- Authors / Org: Security research team, April 2026
- Core finding: Evaluation of DKnownAI Guard, AWS Bedrock, Azure Content Safety, and Lakera Guard reveals 30–70% variance in defense effectiveness across attack vectors (prompt injection, tool misuse, unsafe output). Layered defense effectiveness exceeds linear combination.
- Implication for harness design: Never rely on a single guardrail tool. Prompt filters + tool schema validation + runtime permission checks are mandatory. Regular security audits track evolving guardrail-bypass attacks.
![]()
Production Patterns & Practitioner Insights
Pattern: Dependency Injection via System Prompt Memory
- Context: Production teams using Pydantic AI and CrewAI seek integration paths for external memory systems (Mem0, etc.) with agents.
- Problem: Querying memory as vector embeddings on every request and injecting into prompts is costly and creates memory consistency issues. Multi-agent systems suffer from memory conflicts.
- Solution / Takeaway: Use the
@agent.system_promptdecorator to inject memory clients as dependencies, dynamically updating system prompts at runtime. This pattern is now considered the most production-accurate integration approach. Perform memory lookups during agent initialization to eliminate loop overhead.
Pattern: File-Backed Autonomous Research Environment (SIBYL System)
- Context: Autonomous research agents performing complex multi-step experiments need reproducibility and observability.
- Problem: Agent internal state exists only in memory, making recovery after crashes, failures, or interrupts impossible. Research reproducibility breaks. No audit trails.
- Solution / Takeaway: Persist research state, plans, and outputs to the file system, creating inspectable audit logs. Each agent step's output syncs to disk, enabling failure-point reproduction. This pattern dramatically improves autonomous agent reliability and transparency. Rollback, branching, and experiment comparison work like version control.
Pattern: Actual Framework Selection Criteria (Seven Frameworks in Production)
- Context: One developer deployed seven agent frameworks to production sequentially, accumulating insights on real operational costs.
- Problem: Framework documentation emphasizes strengths; operational costs, debugging difficulty, and team onboarding time remain hidden. Early choices explode costs six months later.
- Solution / Takeaway: (1) Memory system matters more than framework—verify your choice doesn't force-lock you into one. (2) Tool interface consistency—check version-management ease for prompts and tool schemas. (3) Community size vs. documentation quality—GitHub issue response time matters more than star count. (4) Production permission models—CrewAI's role-based permissions bootstrap faster than LangGraph's manual setup, but complex policies favor LangGraph's flexibility. (5) Context management—without cost control, agents become unusable within three months.

Trending OSS Repositories
-
ai-boost/awesome-harness-engineering — Interactive reference and tooling collection consolidating complete runtime discipline for production agents. Includes loop budgets, typed tools, permission gating, compression, prompt caching, and launch checklists. Active updates within the past two days.
-
ARUNAGIRINATHAN-K/awesome-ai-agents-2026 — Curated list of 300+ AI agents, frameworks, and coding tools, organized by category. Includes comparison guides and benchmarks for creative, voice, research, and enterprise agents. Updated five days ago.
-
tmgthb/Autonomous-Agents — Daily-updated list of autonomous agent research papers. Collects SIBYL system file-backed audit patterns and latest multi-agent architecture papers.
Deep Dive: Context Cost Crisis and Five-Layer Safety Architecture in Production Agents
The production AI agent community faces an urgent problem: exponential growth in context window costs. Per Anthropic's new guidance, long-running agents (autonomous coding, multi-step research) must re-present prior conversation history at each step, so token costs grow not linearly with task steps but quadratically. The first 100 steps cost little, but costs explode near 1,000 steps.
Claude Agent SDK's compression feature summarizes conversation history periodically, cutting context windows by over half. For example, compressing "over the last 50 steps, we decided to integrate library X and agreed to use version Y" reduces 2,000 tokens to 200. This clarifies that memory systems are the core cost driver of harness design.
More critically, security architecture must be layered. The five-layer model emphasized by arXiv 2603.05344 and Anthropic's practitioner guidance is:
- Prompt-level guardrails: System prompts block policy violations at the LLM itself.
- Schema-level tool gating: Certain roles or permission levels are barred from specific tools via schema validation.
- Runtime approval systems: Dangerous tools (file deletion, external API calls) require human confirmation, cached as persistent permissions.
- Tool-level validation: Tools themselves perform input range checks and output sanitization.
- Custom lifecycle hooks: Execute custom policies before/after tool execution.
Per arXiv 2604.24826, single guardrails (AWS Bedrock Guardrails alone) achieve only 60–70% blocking rates against prompt injection. Layered defense reaches 95%+. This means guardrails are not one abstraction but a concrete combination of implementations.
OpenAI's Symphony standard automates this. When Codex CLI learns existing harness templates and auto-generates new agent repositories with pre-configured CI, formatting, and packages, every agent starts with a five-layer safe architecture in place.
Framework selection criteria have also evolved. Per the dev.to seven-framework comparison:
- LangGraph: When flexibility and low-level control are needed. Manual permission models suit highly customized policies.
- CrewAI: Fast prototyping. Role-based permissions and tool assignment feel intuitive. Choose when speed of initial build wins.
- AutoGen: For multi-turn negotiation and dynamic team composition. Strong on complex multi-agent workflows.
Yet all comparisons reach the same conclusion: memory systems matter more than frameworks, and harness context-management policies can nullify framework choice.
What to Watch Next Week
- Anthropic Opus 4.6 agent benchmark results: Track whether the 42% CORE-Bench score from Opus 4.5 improves in 4.6. Verify harness simplification actually connects to performance gains.
- CrewAI v3.0 memory API stabilization: If alpha-stage memory persistence launches as stable, validate solutions for multi-agent memory consistency problems.
- LangGraph "tool trust score" mechanism white paper: Tool-call history probabilistically informs future tool approvals. Next evolution beyond persistent permission caches.
Reader Action Items
- Implement context compression policy: If current agents exceed 200-step operations, adopt Claude Agent SDK compression API or equivalent summarization. Target 30–50% context cost reduction. Priority: long-running autonomous coding agents.
- Audit five-layer safety architecture: Verify existing agent harnesses implement (1) system-prompt policy, (2) tool schema gating, (3) runtime approval, (4) tool input validation, and (5) lifecycle hooks. Add missing layers via ai-boost/awesome-harness-engineering guide.
- Abstract memory systems: Stop coupling to framework-native memory. Design adapter layers separating external memory systems (Mem0, custom vector DBs) from framework choice. Adopt
@agent.system_promptinjection pattern to zero out memory-swap costs.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

