AI 모델 벤치마크 업데이트 — 2026-05-31
최근 24시간 동안의 AI 벤치마크 데이터를 보면 GPT-5.5와 Claude Opus 4.7이 서로 다른 분야에서 1위를 다투고 있어요. GPT-5.5는 에이전트 태스크에서, Claude Opus 4.7은 코딩 작업에서 강세를 보입니다. DeepSeek V4의 가성비와 Gemini 3.1의 추론 능력 향상도 눈에 띄네요.
AI 모델 벤치마크 업데이트 — 2026-05-31
1. 챗봇 아레나(LMSYS) 리더보드 순위
현재 Open LLM Leaderboard의 데이터에 따른 주요 모델별 성능 특징입니다:
| 모델명 | 주요 강점 | 성능 특징 |
|---|---|---|
| GPT-5.5 | 에이전트 태스크 | 복잡한 다단계 작업에서 최고 성능 |
| Claude Opus 4.7 | 코딩 성능 | 소프트웨어 엔지니어링 작업에서 선도 |
| Gemini 3.1 | 추론 능력 | 논리 및 수학 문제 해결 우수 |
| DeepSeek V4 | 비용 효율성 | 가장 낮은 추론 비용으로 경쟁력 있는 성능 |
2. 주요 벤치마크 모델 분석
GPT-5.5: 에이전트 태스크 리더
GPT-5.5는 DeepSWE AI 코딩 벤치마크에서 Claude Opus 4.7과 경쟁하며 특정 영역에서 우위를 점했습니다. 복잡한 에이전트 기반 작업과 다중 단계 추론에서 특히 강점을 보입니다.
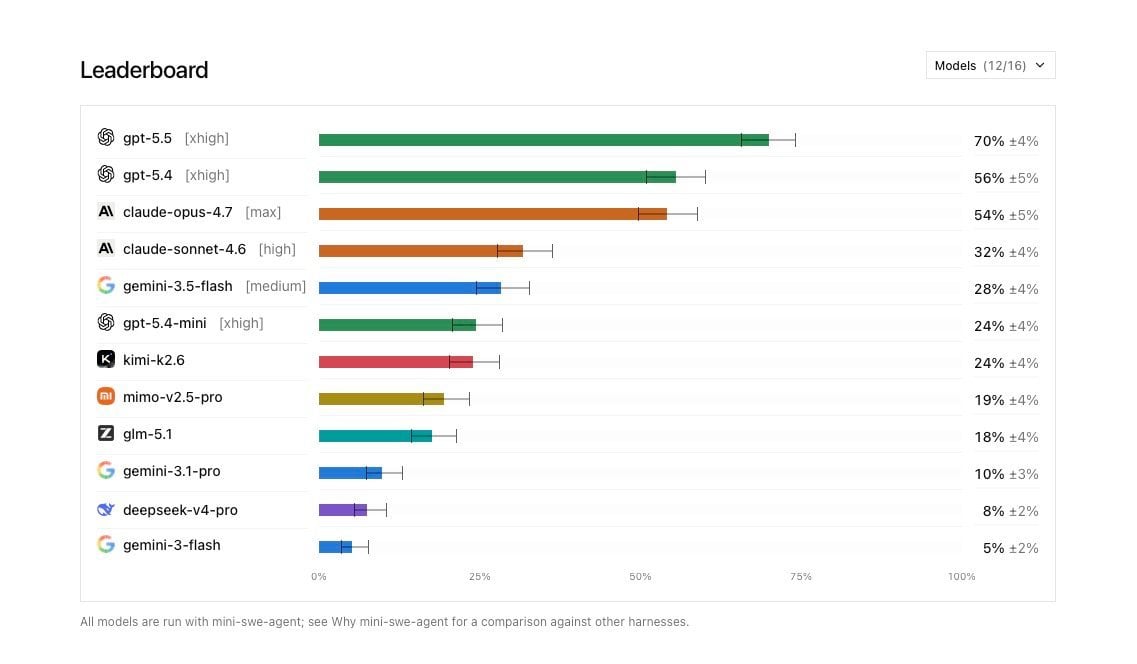
Claude Opus 4.7: 코딩 우수성
Claude Opus 4.7은 코딩 정확도와 효율성 면에서 여전히 강력합니다. 2026년 5월 이후 30일 동안 19개의 새로운 모델이 쏟아져 나왔음에도 불구하고, Opus 4.7은 코딩 벤치마크에서 건재함을 과시하고 있습니다.
Gemini 3.1: 추론 능력 강화
Gemini 3.1은 추론 작업의 강자입니다. 특히 복잡한 논리 문제나 수학 문제를 풀 때 뛰어난 성능을 보여줍니다.
3. 벤치마크 방법론 및 추가 지표
LMArena(이전 LMSYS Chatbot Arena) 평가 방식
LMArena는 아주 독특한 평가 방식을 씁니다. 똑같은 프롬프트를 두 개의 익명 모델에게 던져주고, Bradley-Terry 최대 우도 추정량을 활용해 순위를 매깁니다. 단순히 정해진 답을 맞히는 기존 벤치마크와 달리 실제 사용자들이 뭘 더 선호하는지를 반영하죠.

2026년의 주요 평가 지표
현재 AI 업계는 30개가 넘는 다양한 LLM 벤치마크를 섞어서 씁니다. MMLU부터 Chatbot Arena까지, 각기 다른 벤치마크들이 추론, 코딩, 수학 등 특정 능력을 정밀하게 측정하고 있습니다.
4. 주목할 만한 성능 변화 및 동향
훈련 데이터 오염(Data Contamination) 문제 해결
2026년 들어 가장 중요한 변화 중 하나는 DeepSWE 벤치마크의 도입으로 훈련 데이터 오염 문제를 해결했다는 점입니다. 모델이 미리 테스트 문제를 본 적이 없도록 설계되어 훨씬 믿을 수 있는 결과를 얻을 수 있습니다.
추론 비용의 급락
최근 추론 비용이 무려 80%나 줄었습니다. 덕분에 고성능 모델을 훨씬 저렴하게 쓸 수 있게 되었죠. DeepSeek V4 같은 모델들이 가격 경쟁력을 높이는 데 앞장서고 있습니다.

2026년 5월의 봇물 터지는 모델 출시
5월 한 달 동안만 19개의 신규 AI 모델이 출시되었습니다. 그만큼 혁신 경쟁이 뜨겁다는 증거겠죠. Gemini 3.5 Flash, Composer 2.5, Grok Build, Gemini Omni, Antigravity 2.0 등이 주목받고 있습니다.
주의: 이 보고서의 비교 자료는 공개된 벤치마크 데이터일 뿐이며, 실제 사용하시는 환경에 따라 성능은 다를 수 있습니다. 자세한 내용은 원문 소스를 참고해 주세요.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

