AI Model Benchmark Report — 2026-07-14 현황
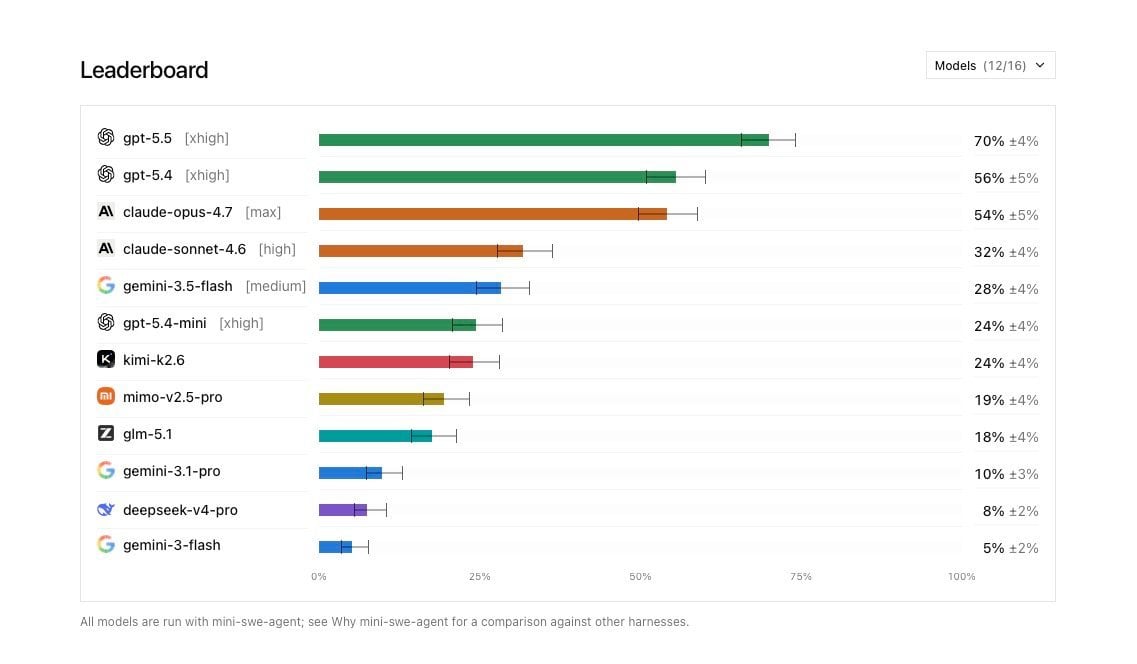
The past 24 hours were dominated by the wide release of OpenAI’s GPT-5.6, while Claude Fable 5 continues to lead coding tasks with a 95.0% success rate on SWE-bench. GPT-5.6 Sol has achieved a 54% improvement in token efficiency for agentic coding.
5 min read/15 sources