Data Engineering & MLOps — June 17, 2026
Databricks unveiled Lakehouse//RT, a real-time analytics engine powering millisecond-latency queries at massive scale, alongside Agent Bricks for agentic AI workflows. Azure Databricks announced governance updates for the agentic era. The industry is converging on unified data platforms that eliminate traditional ETL pipelines for AI workloads.
Data Engineering & MLOps — June 17, 2026
Key Highlights
Lakehouse//RT Brings Real-Time Analytics to Delta Lake
Databricks launched Lakehouse//RT, powered by a new compute engine called Reyden that delivers millisecond query latency at tens of thousands of concurrent users and agents directly on governed Delta Lake and Apache Iceberg tables. The platform solves a decades-old problem: the need to maintain separate transactional and analytical data stores. Customers report sub-100ms latency without ETL pipelines, eliminating the data pipeline bottleneck that has slowed AI agents in production.

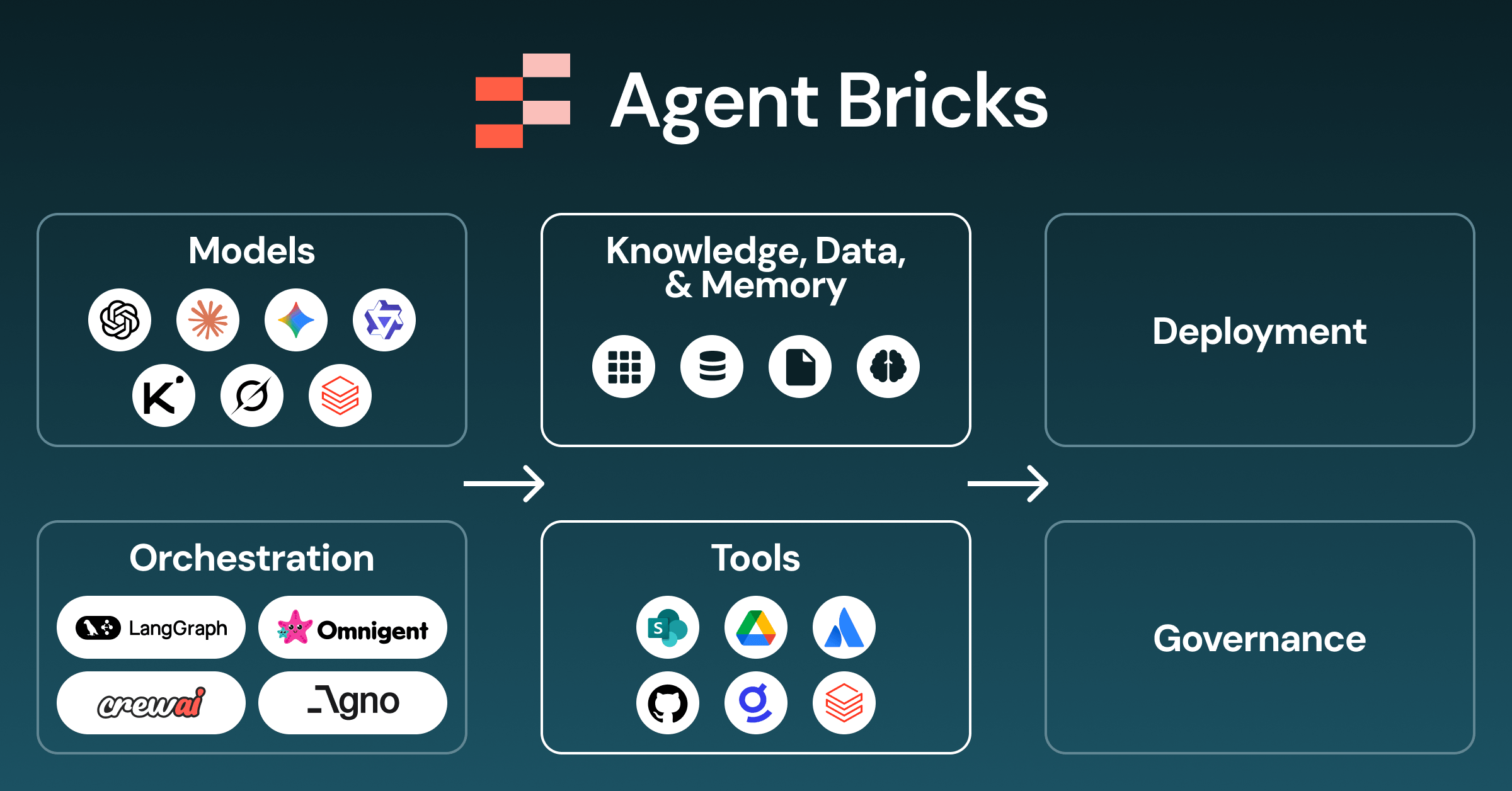
Agent Bricks: Comprehensive Agent Development Platform
Databricks unveiled Agent Bricks at Data + AI Summit 2026, a full-stack agent platform that gives developers model choice, context control, and production governance. The platform integrates with Lakehouse//RT to enable agents to query live data at scale without traditional data movement overhead.
Azure Databricks Adds Real-Time Warehousing and M365 Integration
Azure Databricks announced updates including real-time data warehousing capabilities, built-in AI assistants integrated into Microsoft Teams and M365 Copilot, plus agentic marketing capabilities. The emphasis is on unifying data and governance for agentic workloads while maintaining enterprise security postures.

The End of Pipelines: Unified Operational and Analytical Data
Databricks declared the end of ETL pipelines by unifying operational (transactional) and analytical data on a single platform. LTAP (Lakehouse Transactional Analytical Platform) architecture eliminates the traditional separate systems pattern, allowing agents and analytics to operate directly on the same governed data without data movement delays.
Storage Ecosystem for Multi-Cloud Data Governance
Databricks announced its Storage Ecosystem, fueled by open source OpenSharing, enabling enterprises to govern on-premise data using modern cloud practices. Organizations can now leverage Databricks' data intelligence platform across hybrid environments without forcing data migration to cloud.
Analysis
Solving the Data Pipeline Bottleneck for AI Agents
The announcements converge on a single architectural shift: real-time unified data platforms eliminate the traditional ETL bottleneck that constrains AI agent performance.
Historically, machine learning systems required separate data warehouses for analytics and operational databases for transactions. Data engineers spent weeks building ETL pipelines to move data between systems. When AI agents needed fresh data to make decisions, they faced minutes or hours of latency—unacceptable for real-time fraud detection, pricing optimization, or customer service automation.
Lakehouse//RT and LTAP solve this with millisecond latency on governed Delta Lake tables. Agents query live data directly without pipeline delays. Feature stores and real-time indexes built into the lakehouse eliminate the need for separate feature databases.
The practical impact: organizations deploying agents can now operate on sub-100ms data freshness at scale—tens of thousands of concurrent agent queries—with governance and ACID compliance baked in. This shifts the engineering burden from "build faster pipelines" to "ensure data quality and access control," both MLOps concerns aligned with software engineering best practices.
Governance as a First-Class Problem
Azure Databricks' M365 integration and built-in AI assistants signal that governance isn't bolted on after deployment—it's now foundational to platform architecture. Teams can't ship agentic systems without auditability, compliance, and fine-grained access control. The convergence of MLOps and data governance suggests that future enterprise ML tooling will make separation between these concerns obsolete.
What to Watch
- Databricks Data + AI Summit 2026 — Keynote announcements and customer case studies for Lakehouse//RT adoption across fintech, healthcare, and retail
- Apache Iceberg open table format standardization — how Iceberg adoption in Lakehouse//RT may shift the broader data lakehouse market
- Competing agentic data platforms — Snowflake, Microsoft Fabric, and cloud-native providers' responses to unified real-time data architectures
- MLOps maturity benchmarks — industry standards for agent pipeline governance, versioning, and reproducibility in production environments
FRESHNESS NOTE: All sources published or updated between June 10–17, 2026. Data Engineering Weekly coverage focused on the Databricks Data + AI Summit 2026 announcements and their impact on ML production systems and real-time analytics patterns.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

