Data Engineering & MLOps — 2026-04-17
Databricks continues its rapid platform evolution this week, publishing new content on real-time product search with Vector Search and Lakebase, and deepening its dbt integration story for unified pipelines. Meanwhile, the MLOps community is actively discussing scalable deployment best practices as AI workloads grow more complex, with fresh guidance on CI/CD, monitoring, and production-grade architecture emerging just days ago.
Data Engineering & MLOps — 2026-04-17
Key Highlights
Databricks Launches Real-Time Product Search Architecture
Databricks published a detailed engineering post this week on building real-time product search using its Vector Search, Lakebase, and AI agent capabilities. The article demonstrates how teams can deliver fast, personalized search results at scale — a pattern increasingly relevant for e-commerce and recommendation use cases moving to the lakehouse.
dbt on Databricks: Open Platform, Unified Pipelines
Also published this week, Databricks made the case for why dbt adoption on its platform is accelerating. The post frames the combination as an "open platform" story — teams get unified SQL transformation pipelines without sacrificing flexibility, governance, or interoperability with the broader data ecosystem.

MLOps Best Practices for Scalable Deployment in 2026
Published just four days ago, a comprehensive guide on kernshell.com covers practical MLOps best practices for scalable, secure ML deployment in production environments. Topics include architecture patterns, CI/CD pipelines, monitoring strategies, and enterprise deployment challenges — reflecting how teams are operationalizing AI at scale in 2026.
Analysis
The dbt + Lakehouse Convergence
One of the clearest structural trends visible this week is the deepening integration between dbt (data build tool) and the lakehouse paradigm. Databricks' new post on unified pipelines highlights a maturing story: for years, dbt was the tool of choice for analytics engineers working in the cloud warehouse world (Snowflake, BigQuery, Redshift). Its arrival as a first-class citizen on the Databricks lakehouse signals that the boundary between data warehouse and data lake workloads is continuing to dissolve.
The significance for data engineering teams is practical: rather than managing separate transformation toolchains for structured analytics versus ML feature pipelines, teams can unify both workflows on a single platform. SQL-centric transformations via dbt can feed directly into downstream ML workloads managed by Unity Catalog, MLflow, and now Lakebase — Databricks' newly introduced managed PostgreSQL-compatible database.
The real-time product search architecture also published this week illustrates a complementary vector: AI-native applications that require millisecond-latency retrieval are increasingly being built on top of the lakehouse, rather than as separate standalone systems. The combination of structured data governance (Delta Lake, Unity Catalog) with vector retrieval and agent orchestration is emerging as a preferred pattern for production AI applications.
Together, these two announcements reinforce a single architectural thesis: the modern data stack is consolidating. Transformation, storage, governance, ML, and application retrieval are being pulled toward fewer, more integrated platforms.
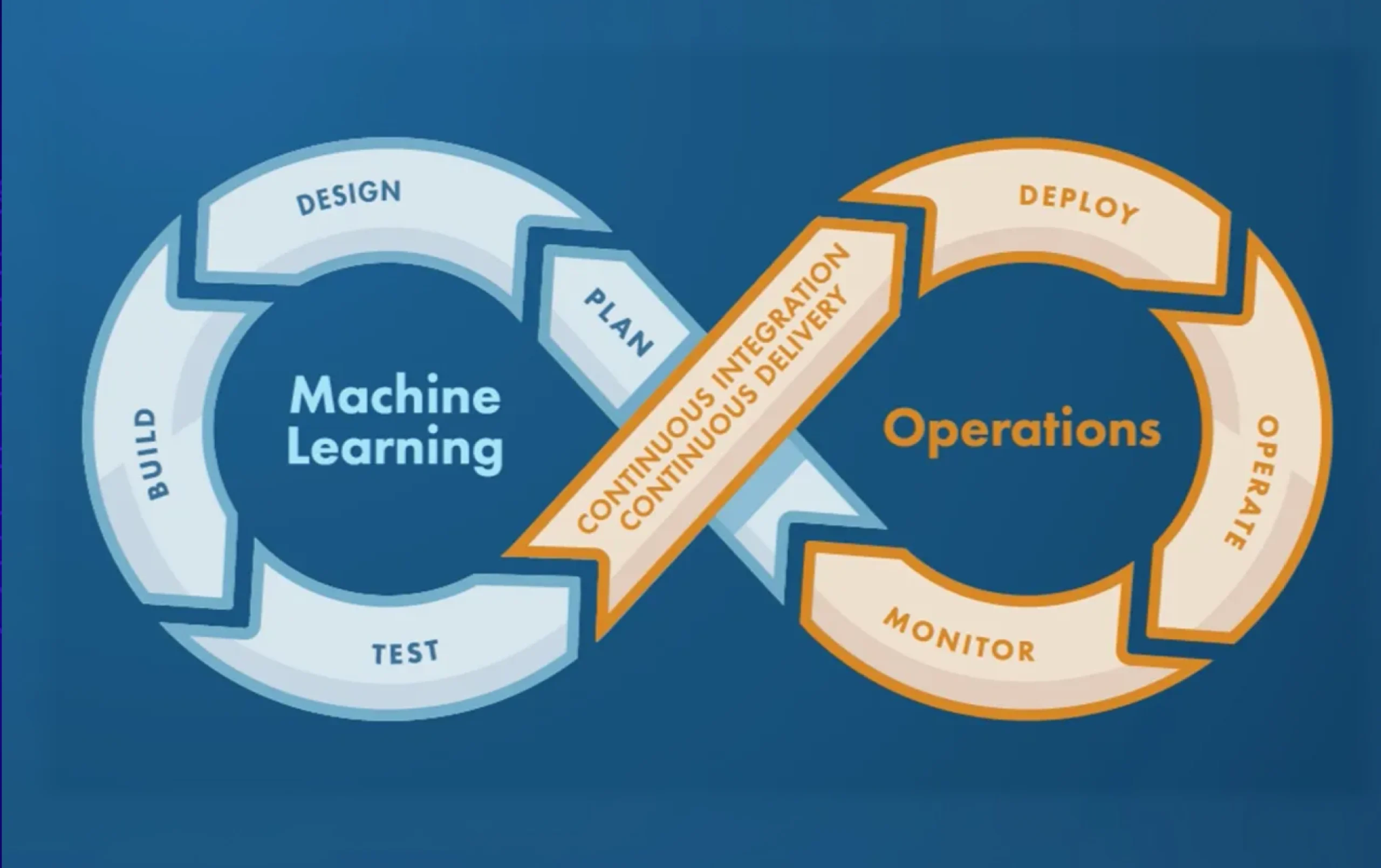
MLOps Maturity: From Experiment to Production at Scale
The scalable deployment guide published this week echoes a theme dominating enterprise MLOps conversations: the gap between training a model and reliably running it in production remains the central challenge. Key recurring practices highlighted in fresh 2026 guidance include:
- CI/CD automation for model retraining and deployment pipelines, treating model releases like software releases
- Adaptive scaling based on latency and traffic demand — static provisioning is increasingly insufficient for production ML workloads
- Monitoring beyond accuracy — tracking data drift, feature distribution shifts, and infrastructure health alongside model performance metrics
These patterns reflect a field that has moved past the "let's build a proof of concept" stage and is now wrestling with the operational realities of ML at scale: reproducibility, incident management, and cross-team ownership of production systems.
What to Watch
- Databricks Data + AI Summit is scheduled for June 15–18 in San Francisco, with early registration pricing ending April 30. Given the pace of Databricks product announcements (Iceberg v3, Lakebase, Vector Search, dbt integration), the summit is expected to feature significant new platform announcements.
- Watch for continued evolution of the Apache Iceberg v3 public preview on Databricks, announced last week, as teams begin testing new table format capabilities in pre-production environments.
- The dbt + Databricks integration story is still early — expect documentation, community tutorials, and production case studies to emerge over the coming weeks as teams move from reading blog posts to implementing unified pipelines.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

