Today’s VLM & VLA Research Briefing — 2026-07-05
Recent research in VLM and VLA focuses on practical AI, highlighting breakthroughs in hand gesture recognition, robotics, and the new MARS2 competition at ECCV 2026.
Today’s VLM & VLA Research Briefing — 2026-07-05
Notable New Papers
![]()
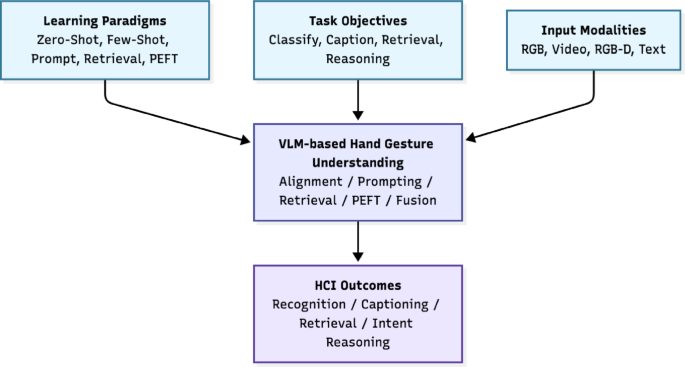
Applying Vision-Language Models to Hand Gesture Recognition
A recent study introduces a methodology for applying large Vision-Language Models (VLMs) to Hand Gesture Recognition (HGR). The core contribution is overcoming the limitations of traditional vision-only systems by providing semantic grounding. This suggests that VLMs can be used directly to improve user interfaces beyond simple image analysis.
ECCV 2026 MARS2 Multimodal Reasoning Competition Launch
The MARS2 (Multimodal Reasoning and Synthesis) workshop and competition has officially launched at ECCV 2026, the premier AI conference held in Guangzhou. Hosted by Tec-Do and MiniMax, this event provides an international platform for advancing multimodal reasoning capabilities.
[2601.03309] VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
[2505.04769] Vision-Language-Action (VLA) Models: Concepts, Progress, Applications and Challenges
[2510.09586] Vision Language Models: A Survey of 26K Papers
[2501.02189] A Survey of State of the Art Large Vision Language Models: Alignment, Benchmark, Evalua
Pure Vision Language Action (VLA) Models: A Comprehensive Survey
Vision-Language-Action (VLA) Models: Concepts, Progress, Applications and Challenges
VLM Technology Trends & Summary
Accelerating Practical MLLMs
Multimodal Large Language Models (MLLMs) are proving their excellence in various vision-language tasks such as image captioning, Visual Question Answering (VQA), cross-modal retrieval, visual grounding, multi-image reasoning, long-video understanding, and Embodied AI. In particular, visual understanding and reasoning abilities have improved significantly, and these technologies are gradually being deployed in real-world environments.
VLM Applications in Hand Gesture Recognition
An open-vocabulary hand gesture recognition system using VLMs has emerged, moving beyond the limitations of traditional closed-set classification. This presents a new path for natural human-computer interaction and demonstrates that VLMs are evolving into tools with high-level semantic understanding beyond simple image analysis.
Promoting Multimodal Model Efficiency
As widespread adoption of MLLMs continues, reducing model size and cutting training/inference costs have become key research challenges. Efficient multimodal model design is becoming an essential prerequisite for the mass adoption of AI systems.
Robotics & VLA Performance Summary
Vibrant Academic Community for VLA Research
Recently, 164 papers on Vision-Language-Action (VLA) models were submitted to ICLR 2026, showcasing diverse research directions including discrete diffusion VLAs, reasoning models, and benchmarks (LIBERO, CALVIN, SIMPLER). This highlights the rapidly growing importance of VLA research in the academic community.
Expanding VLA Models for Drones and Bipedal Manipulation
Research on VLA models for unmanned aerial robots and bipedal manipulation tasks is underway, with various architectures—such as autoregressive, flow-based, diffusion-based, and hybrid—having been announced as of early 2026. These advancements suggest that VLA models are evolving to adapt to a wider variety of robotic platforms.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

