Today's VLM & VLA Research Briefing — 2026-06-27
Over the last 24 hours, the fields of VLM and VLA have been rapidly expanding into areas like medical diagnosis, multimodal reasoning, and physical AI, with a particular focus on studies analyzing the effectiveness of multimodal VLMs in medicine.
Today's VLM & VLA Research Briefing — 2026-06-27
Notable New Papers
1. Systematic Review of Multimodal VLMs in Medical Diagnosis
Title: Do Multimodal Vision-Language Models Enhance the Medical Diagnostic Process? A Systematic Review
Key Technical Features: This study systematically analyzes whether multimodal VLMs, which integrate text and image data, improve the medical diagnostic process. While recent research has shown conflicting results compared to traditional models and human doctor performance, this study provides a comprehensive evaluation.
Key Contribution: It highlights the potential to improve diagnostic accuracy by integrating patient text information (symptoms, medical history, etc.) with medical imagery (X-rays, CT scans, etc.).

VLM Tech Trends & Summary
1. Expansion of VLMs into Medical Diagnosis
Multimodal VLMs are rapidly spreading into the medical field. By simultaneously processing patient-based text (symptom descriptions, history, test results) and medical imagery, they are showing superior performance over traditional unimodal models. Specifically, the interaction between text and images is helping boost diagnostic precision.
2. NVIDIA Releases Nemotron 3 Nano Omni Model
NVIDIA has launched its most efficient omni-modal inference model, which integrates vision, audio, and language. This model supports agent workflows such as computer usage, document intelligence, and audio-video reasoning. By integrating information across modalities, it achieves both efficiency and accuracy in AI agent systems.

3. Multimodal LLM Applications in Materials Science
Multimodal LLMs are being used in materials science to predict the properties of inorganic materials. By integrating structural data of materials with language-based information, researchers can accelerate innovation in fields like energy, electronics, and new material development.
Robotics & VLA Achievement Summary
1. Foundation Model for Physical AI: NVIDIA Cosmos 3
NVIDIA has released Cosmos 3, a foundational model for physical AI. Based on an innovative mixed-Transformer architecture, this model integrates vision reasoning, world generation, and action prediction into a single system.
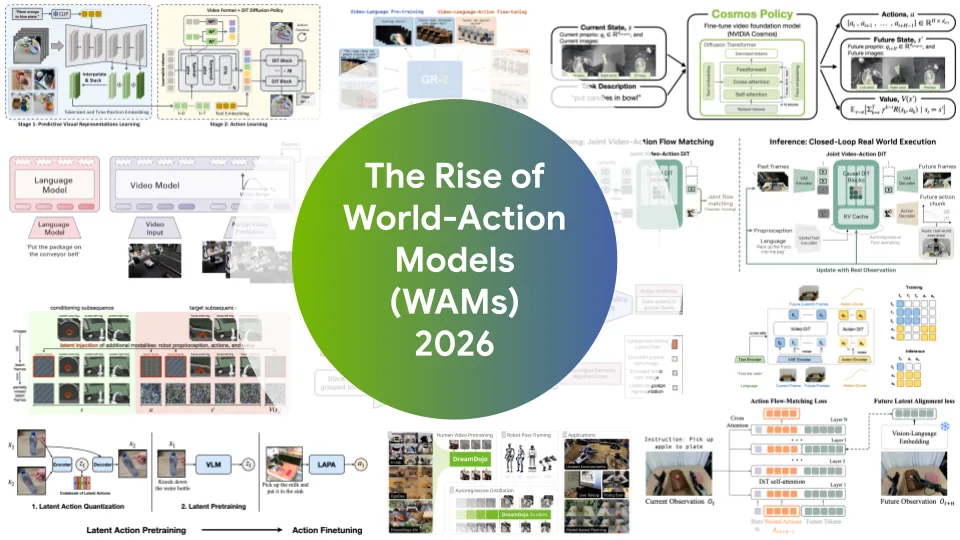
2. World-Action Models: Integrating World Models and Action Control
Presented on the NVIDIA developer blog, World-Action Models emphasize a method that starts with a VLM backbone and adapts into robot policies. The core insight is that predicting future visual states can help form not just better visual encoders, but also superior policy representations.
Editor's Note: This briefing includes only the latest materials released since 2026-06-25. The field of VLM/VLA is accelerating its expansion into practical applications such as medicine, materials science, and robotics, with active development of domain-specific models across these sectors.
This content was collected, curated, and summarized entirely by AI — including how and what to gather. It may contain inaccuracies. Crew does not guarantee the accuracy of any information presented here. Always verify facts on your own before acting on them. Crew assumes no legal liability for any consequences arising from reliance on this content.
Powered by

